
¿Cuáles son los datos fuentes para el sistema de reportes?
Tenga en cuenta: El sistema de reportes de Power BI MINSA tiene 3 tipos de fuentes para alimentar la información representada: Hechos, Dimensiones y Configuración.
Inicialmente nos concentraremos en la globalidad y posteriormente analizaremos en detalle cada fase del proceso.
Archivos fuentes del sistema
Para lograr que el sistema de reportes pueda actualizarse automáticamente, sin intervención humana y sin instalar soluciones tipo Data Gateway sus fuentes debían ser de tipo “Recurso Web”, dicho de otra manera estar compartidos como recursos URL públicos.
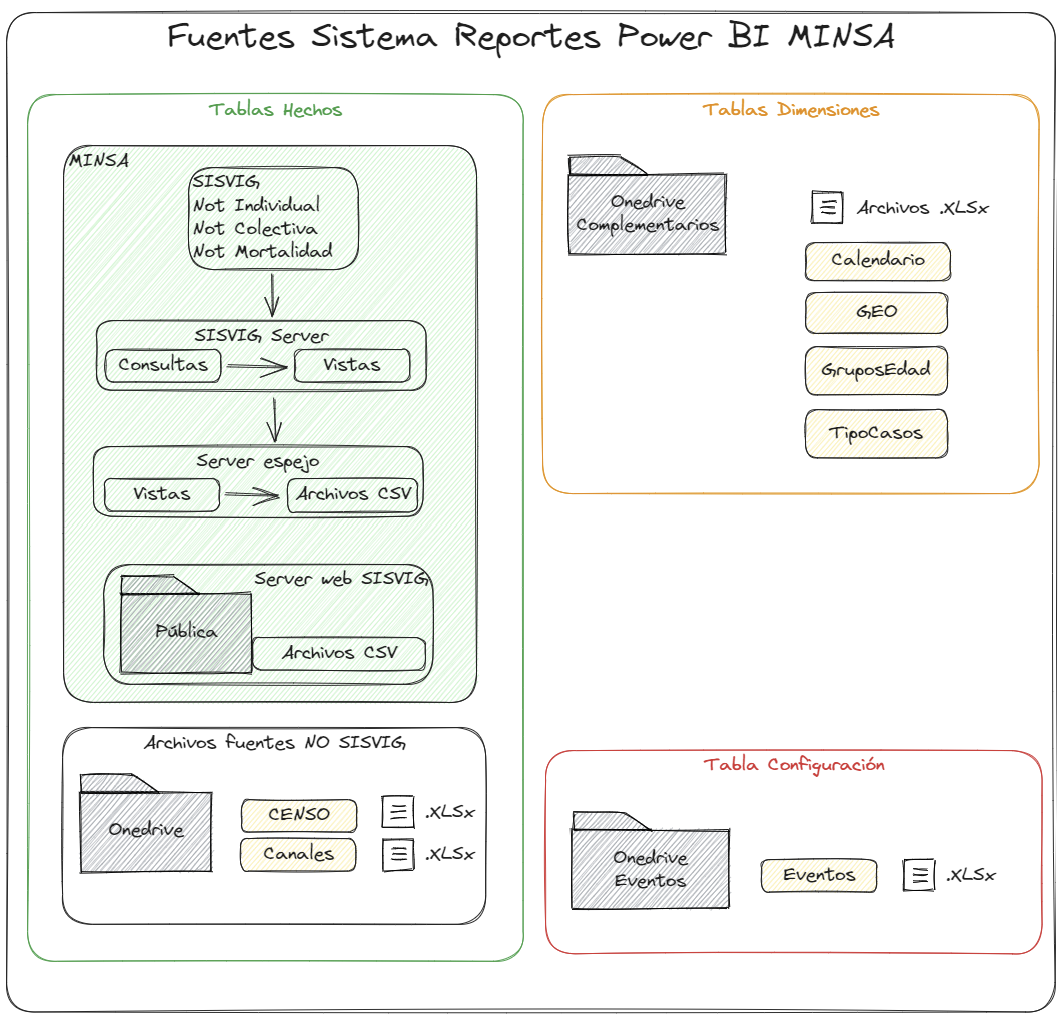
Para minimizar el impacto del requerimiento a los servidores de MINSA se leen solamente las tres tablas de hecho del sistema, notificación individual, notificación colectiva y mortalidad, el resto de tablas (dimensiones y configuración) están disponibles como carpetas de OneDrive y compartidas con el departamento de epidemiología.
Una vez que han sido generadas en SISVIG, estas son llevadas a una carpeta web, el proceso está gobernado por el siguiente script:
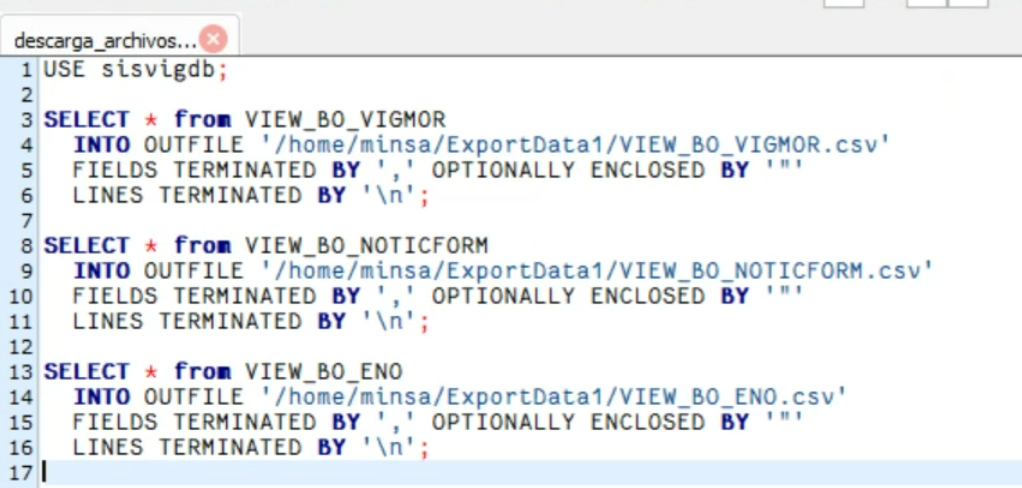
Las consultas oficiales de SISVIG generan 3 archivos de salida, estos son posteriormente compartidos en una carpeta web.
Estructuras de tablas de hechos
Las tablas de hecho son los datos de los eventos, de manera orgánica en SISVIG, estos se dividen en Colectiva, Individual y Mortalidad, la estructura ha sido previamente documentada - ver imagen siguiente:
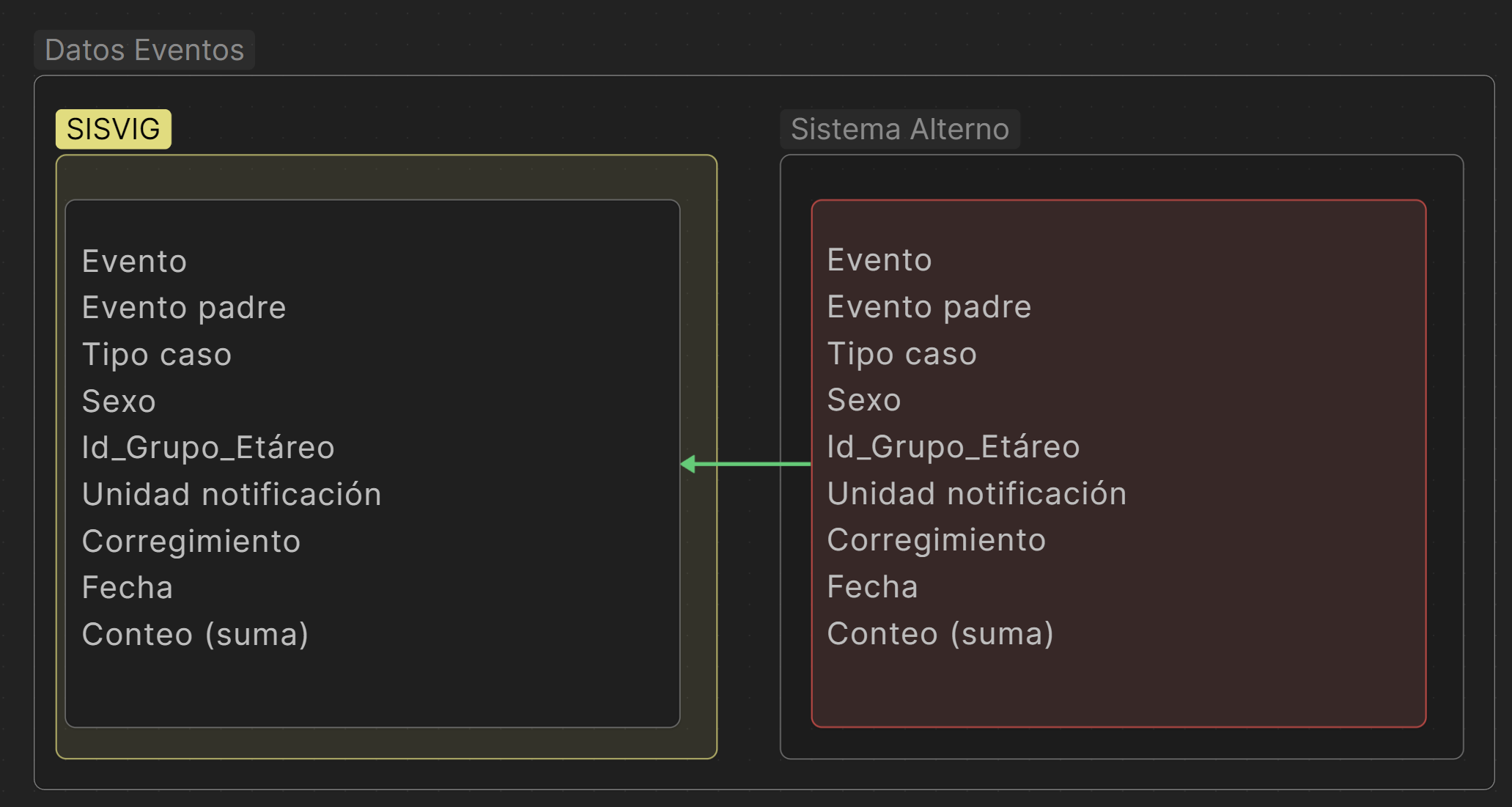
Esta estructura no es copia de la tabla oficial para SISVIG, sino de una consulta donde se han seleccionado columnas clave y datos agrupados, no se pretende reemplazar la documentación del diccionario de datos o modelos entidad relación de la entidad.
Ello permite que si posteriormente se generan cambios en SISVIG, mientras se mantenga la estructura en la nueva versión se garantizaría la continuidad de la funcionalidad del tablero - ya que sin importar la versión o actualización, las columnas seleccionadas son propias para todos los eventos, es decir : evento y evento padre (Actualmente como textos debido a la arquitectura actual del sistema SISVIG), el tipo de caso se determina como confirmados, descartados, etc. el Id del grupo etáreo (aunque es propio de SISVIG puede ser configurado en la tabla de dimensiones), el id de la unidad de notificación y id de corregimiento, la fecha y el agrupador de conteo.
En resumen las tablas de hechos son las únicas que son leídas desde SISVIG, para el caso de CENSO y Canales son tablas de hechos, pero no provienen de este servidor, así que tampoco se subieron allí para descargar sino que se crean directamente como datos disponibles en una carpeta de OneDrive.
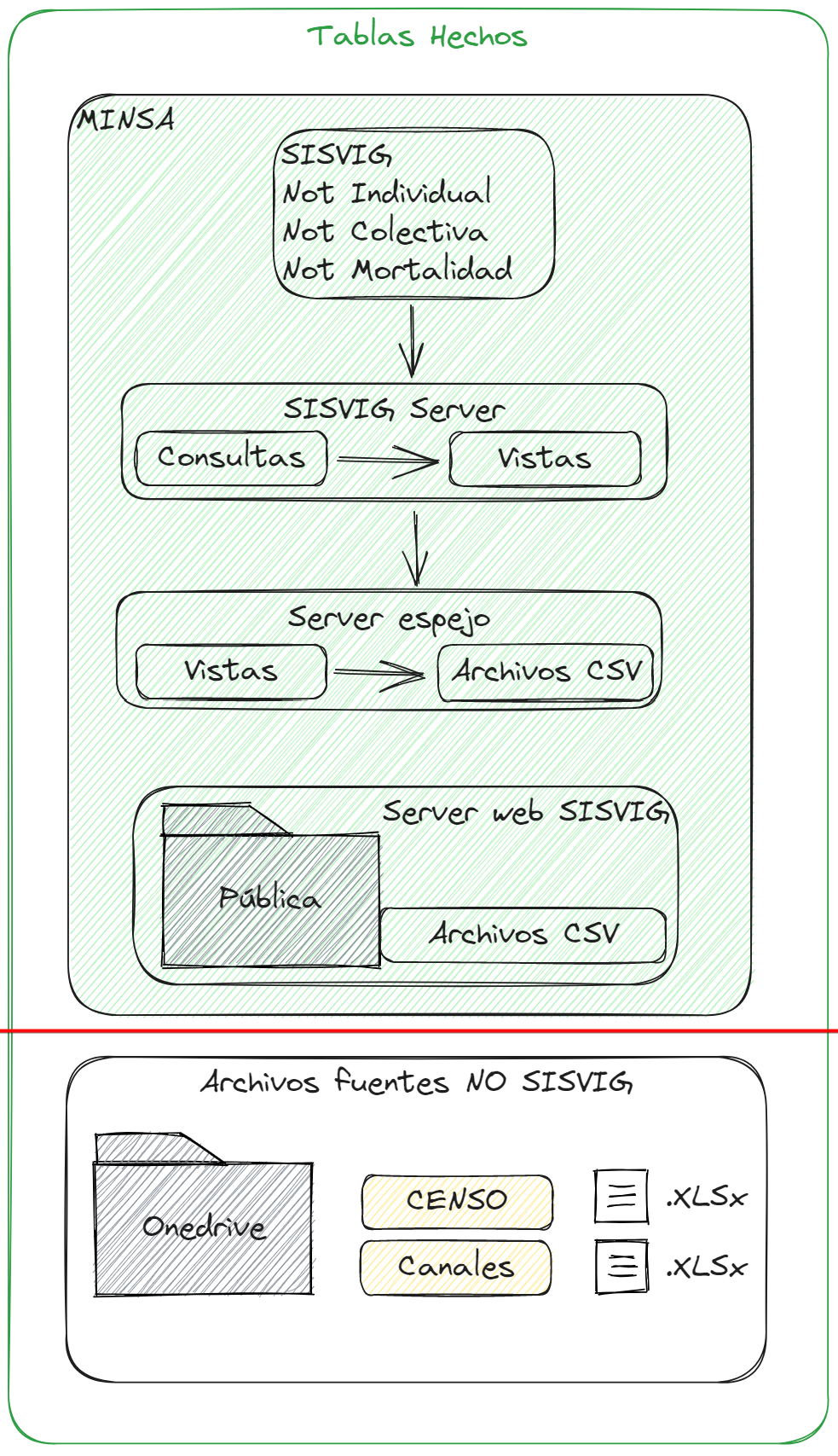
Las tablas generan unas consultas y unas vistas para posteriormente ser subidos a un servidor espejo de MINSA, este servidor espejo posee un script que convierte las vistas a archivos CSV y las pone en una url pública, así que el servidor sufre pocas solicitudes (1 diaria 6 am aprox). Las otras fuentes son web.
Actualizaciones por tipo de datos
Analicemos el siguiente escenario: ¿Qué ocurre si los campos Evento y Evento padre ya no son textos sino que se generan con un ID? claramente el sistema actualmente leerá estos campos como tipo texto, pues así son recibidos directamente.

La arquitectura existente al momento de elaborar esta documentación, arroja los campos de Id_grupo y id_evento_padre como textos, en el ejemplo AFECCIÓN NOSOCOMIAL e IAAS.
Debido a que internamente en las tablas de configuración (ver más adelante) se puede configurar el nombre de cada evento, es viable recibir valores numéricos para este tipo de casos y mantener la operabilidad de los procesos. (se recibe texto al inicio y posteriormente en una actualización se reciben números).
Ello implica que si posteriormente para optimizar las consultas en vez de enviar caracteres se reciben números no hay que configurar nada el el sistema de reportes, aunque es claro que en las tablas de configuración habría que ajustar los nuevos valores y sus equivalencias.
Si desea una optimización mayor, en el sistema de reportes se leen estos valores de textos y se asigna internamente un ID - para optimización, generación de índices, etc. - así que si se leyeran directamente estos valores numéricos como textos se podrían eliminar algunos pasos de los ETL para así asignar un ID.
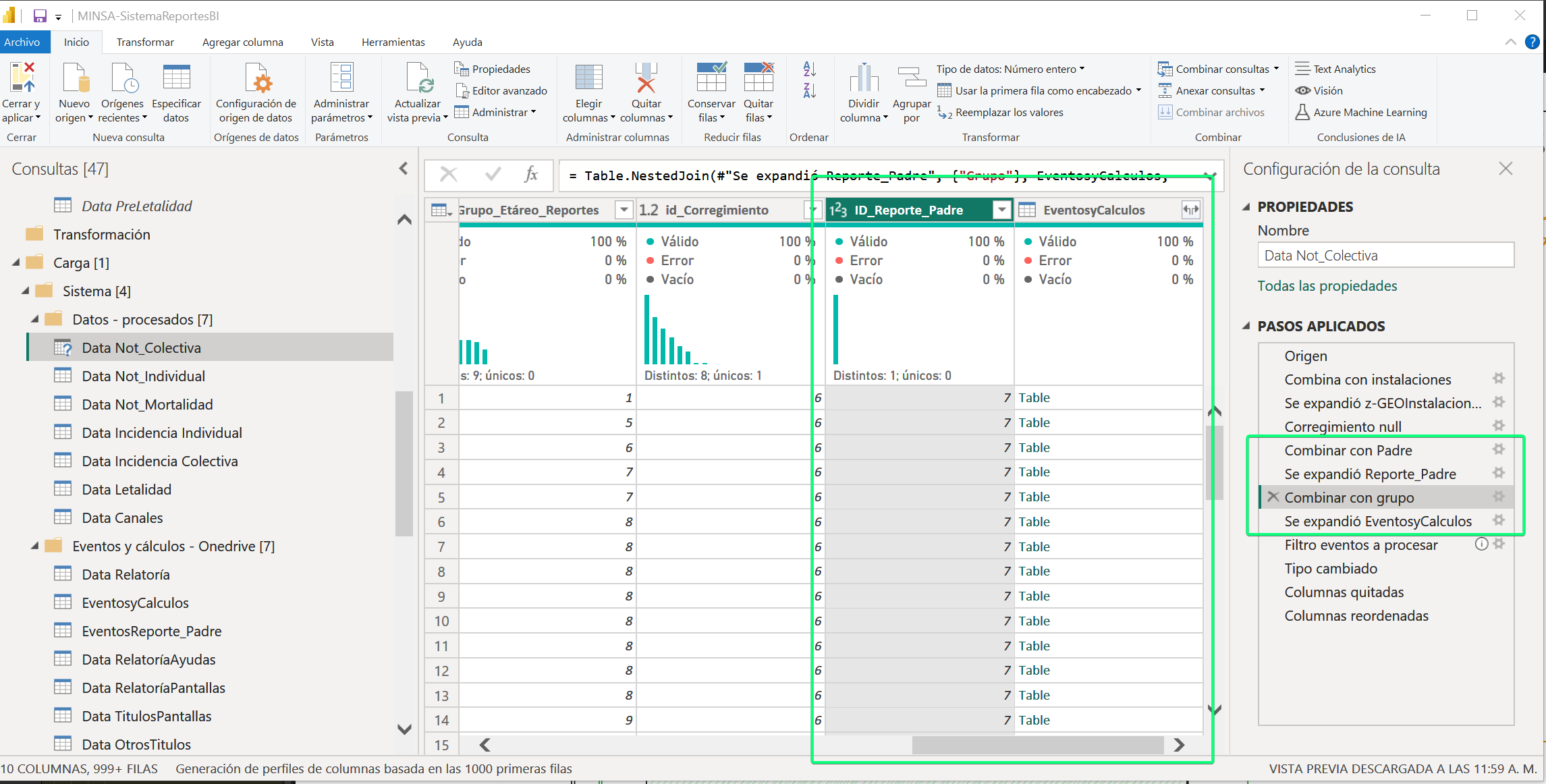
El sistema de reportes a través de las tablas de configuración (hoja eventos) asigna un ID numérico para lograr posteriores relaciones y traer datos de apoyo, por lo cuál si se recibieran datos numéricos, algunos pasos se podrían omitir, optimizando aún más el sistema.
En resumen, aunque el sistema recibe datos de tipo texto dada la naturaleza de los archivos consultados (CSV) estos datos se cruzan junto con las tablas de configuración del sistema de reportes para poder determinar mejores comportamientos, si no se cambian las fuentes, no habría razón para modificar los archivos de configuración, salvo la creación de un nuevo evento - que sería cuestión de actualizar en la configuración.
Estructuras de tablas de dimensiones
Aunque comúnmente en la elaboración de sistemas de reportes en Power BI se suele usar una conexión a una base de datos y consultar sus tablas relacionadas - lo que permite una actualización constante y coherencia en el modelo de datos - también implica una carga más alta para el servidor fuente.
En el sistema de reportes de Power BI MINSA se aislaron las tablas de hechos ya mencionadas (individual, colectiva y mortalidad) de sus dimensiones, básicamente porque en términos generales poseen poca actualización, por ejemplo, es difícil pensar que se crearán nuevos grupos etáreos.
Así que estas tablas de dimensiones se han descargado de SISVIG y se han subido como archivos modificables en Excel Online en OneDrive de Microsoft y han sido compartidos estos archivos al área de epidemiología.
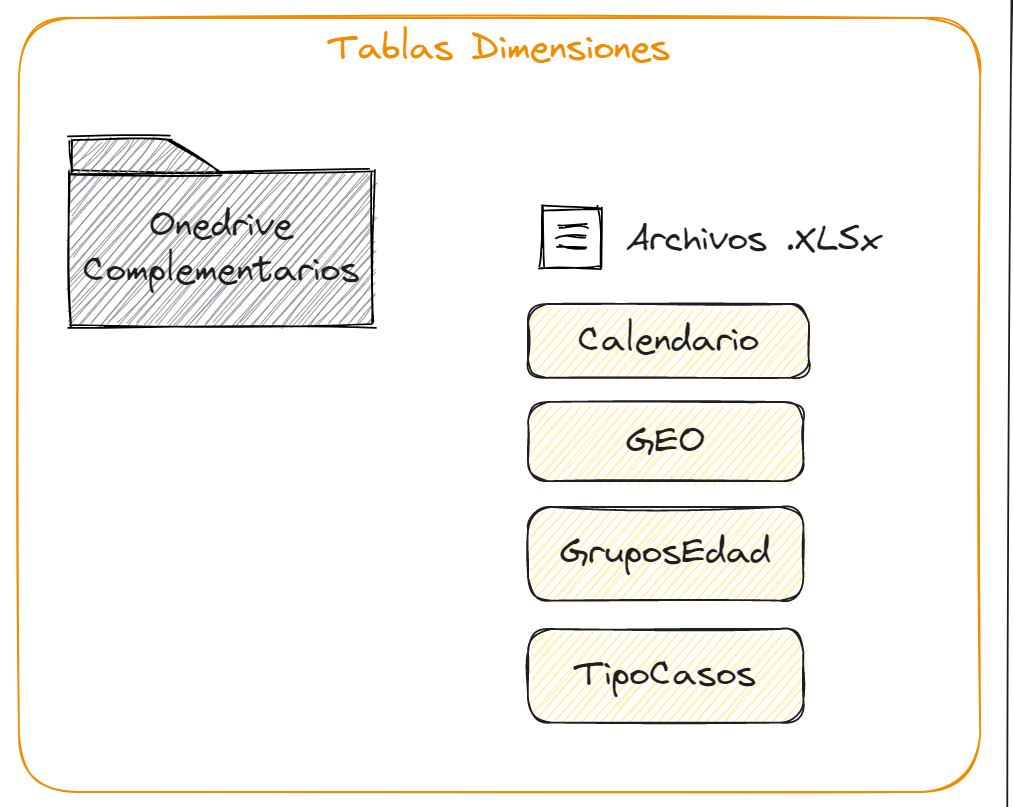
Las tablas TipoCasos, Calendario y Grupos de Edad suelen tener poca actualización, estas son dimensiones, de igual manera el archivo GEO pues allí tenemos estructuradas las tablas de Países, Provincias, Regiones, Distritos, Corregimientos, Instalaciones, Tipos de Instalación, Niveles de Instalación y Sector de Instalaciones.
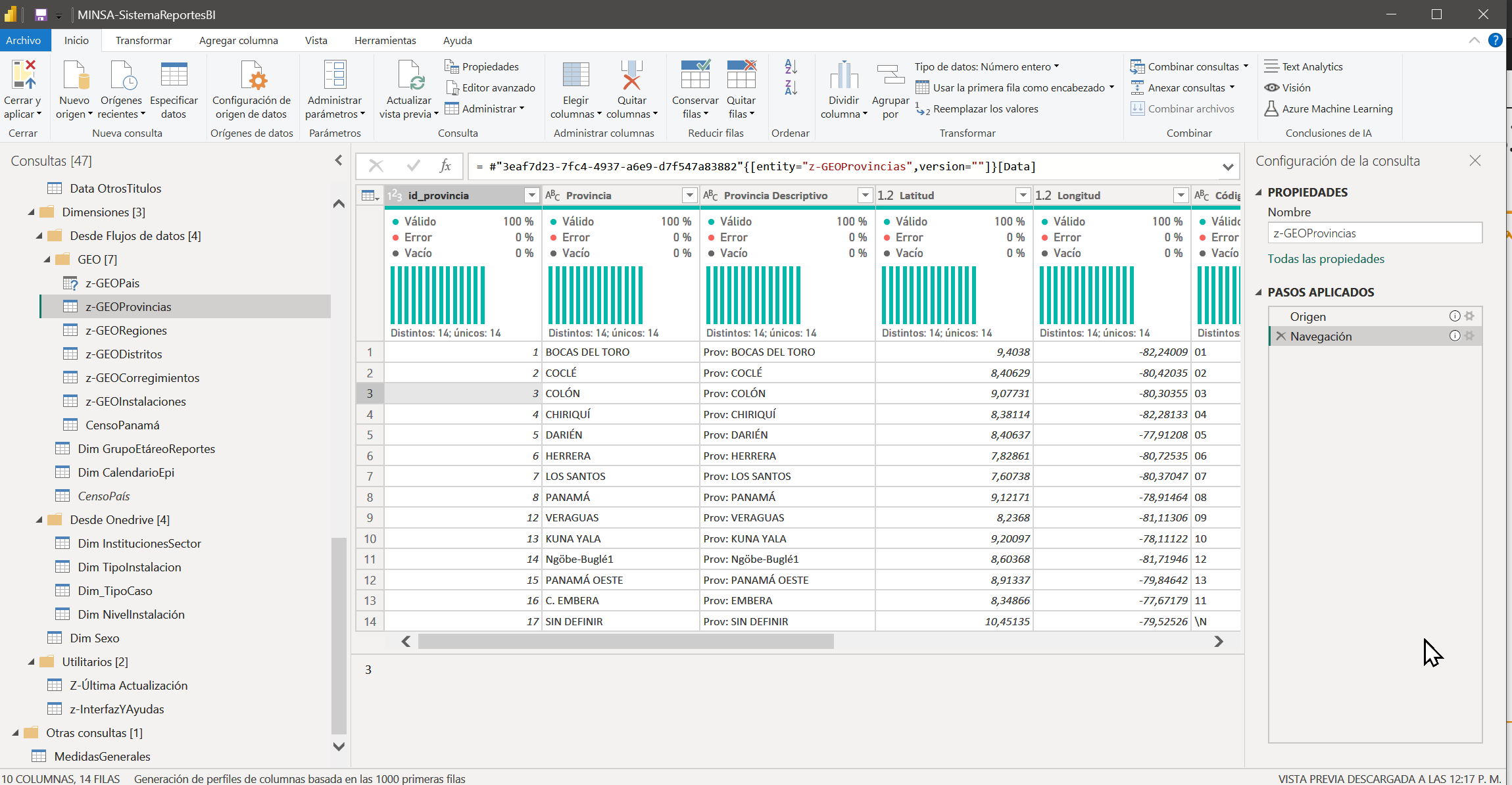
Una tabla común en la dimensión geográfica tendrá asignado un ID (que proviene de SISVIG), un código MINSA - varias posiciones, de tipo texto - y datos de la estructura a la que pertenece junto a datos de longitud y latitud para visualizaciones, por ejemplo una provincia de Panamá, tendrá asignado el ID del país Panamá.
Es decir, los datos de tipo dimensión son los siguientes:
- Calendario Epidemiológico (archivo CalendarioOficial.xlsx)
- Tipo Casos (archivo TipoCasos.xlsx)
- Grupos de edad (archivo GruposEtareos.xlsx)
- Dimensión geográfica (Archivo GeoPanama.xlsx) compuesto de las siguientes hojas:
- Países (hoja GEO_Países)
- Provincias (hoja GEO_Provincias)
- Regiones (hoja GEO_Regiones)
- Distritos (hoja GEO_Distritos)
- Corregimientos (hoja GEO_Corregimientos)
- Instalaciones (hoja GEO_Instalaciones)
- Tipos de instalación (hoja Tipo instalaciones)
- Sectores de institución (hoja Sectores)
- Niveles de institución (hoja Niveles)
Al ser hoja de cálculo en línea, la edición es sencilla y posee una curva de aprendizaje baja, pues es básicamente el manejo de una hoja de cálculo, adicionalmente cada columna suele tener nombres descriptivos y tener claro su uso, por ejemplo, en la dimensión geográfico los nombres de los campos son sugerentes.
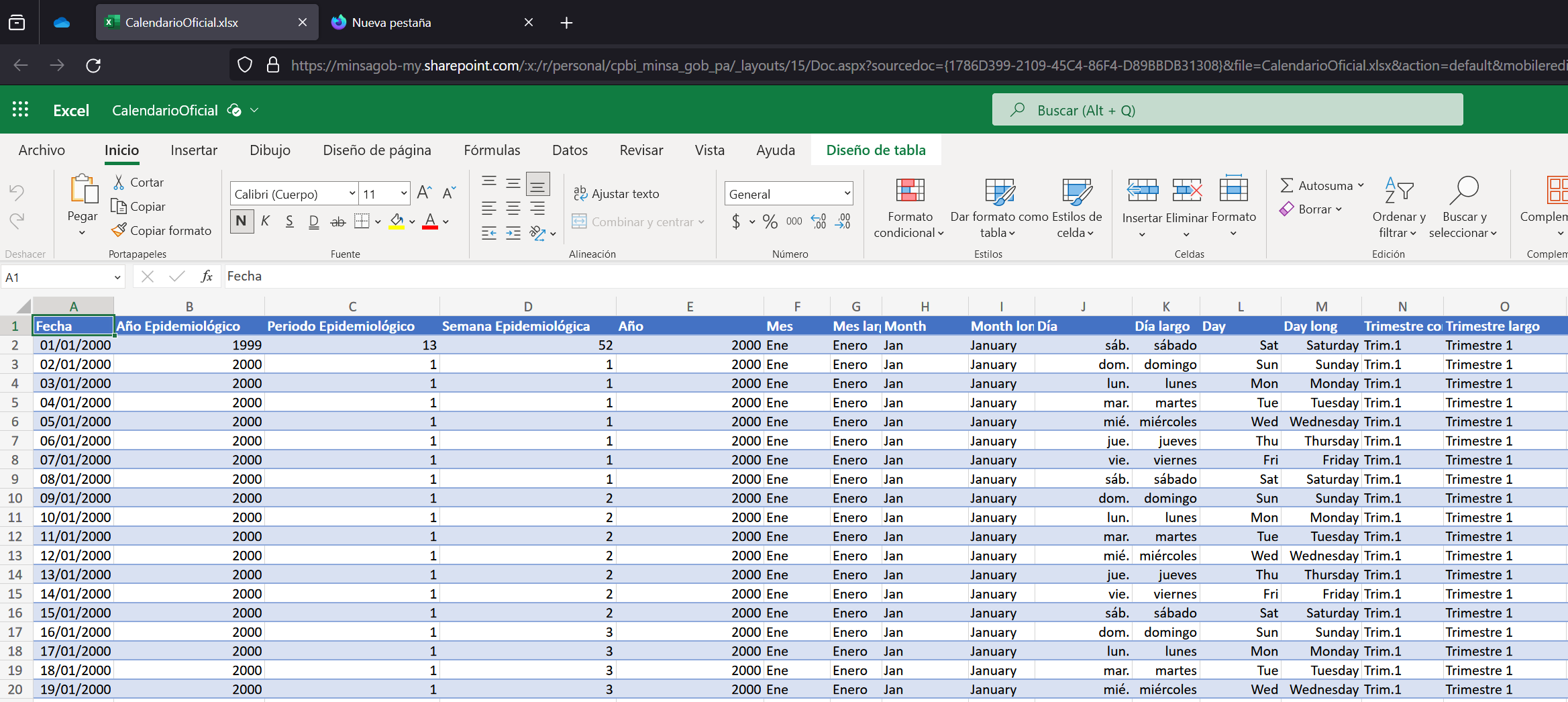
Un usuario que requiere un ajuste en la dimensión geográfica requiere sólo tener permisos de edición y por supuesto editar el valor que requiere cambiar.
Estructuras de tablas de configuración
En el archivo llamado EventosyConfiguración.xlsx se tendrá acceso a diversos valores propios de la configuración del sistema, esto tendrá explicación más detallada en otras páginas de documentación.
Desde este archivo se puede configurar todo el sistema de reportes de Power BI MINSA.