
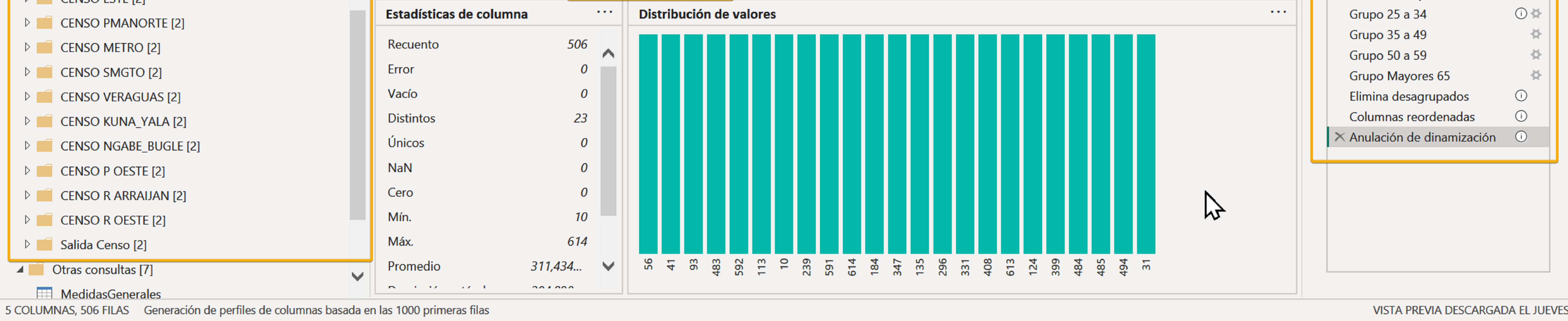
¿Cómo editar la dimensión del censo?
Tenga en cuenta: Los archivos de Excel de Censo son leídos por un ETL que consolida la información, este sistema usa los nombres de las hojas para correr rutinas, sin embargo, usan el código id de SISVIG del corregimiento para asignar la población leída.
Una práctica recomendada es usar la plantilla de población que se entrega con el proyecto, ello permite insertar datos en las estructuras convenidas, otra opción podría ser usar los datos del año inmediatamente anterior, pero con esta técnica se usará tiempo del operador borrando los datos y podría llevar a errores por descuido u olvido.
Estructura para datos de censo
Para calcular datos como incidencias y canales endémicos se requiere la información de población por año, previamente desde el departamento de epidemiología se usaron archivos tipo Excel separados por hojas con los datos respectivos, una estructura típica se vería de la siguiente manera:
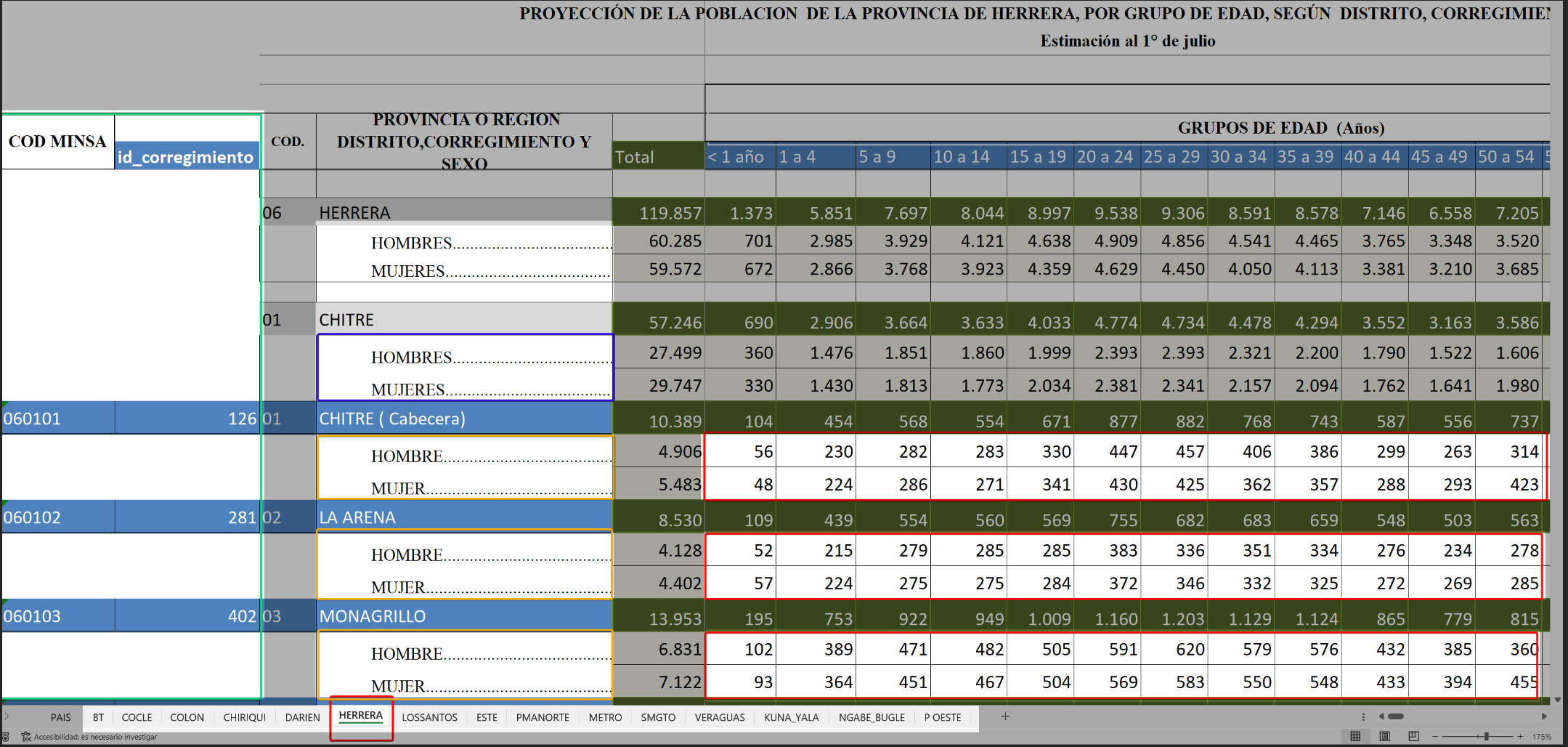
En el lado izquierdo vemos el código MINSA y el id de corregimiento (dado por SISVIG), en el centro vemos categorización de hombre (s) y mujer(es) y al lado izquierdo vemos en celdas blancas sin fondo el valor consignado por grupos de edad según el sexo para una población de corregimiento, abajo, nombres de las hojas que son procesadas.
Vamos a determinar los puntos importantes en esta estructura y determinamos su uso y lectura.
Nombres hojas a procesar.
Los archivos de censo poseen varias hojas, las hojas que se procesan son: CHIRIQUI, BT, COCLE, COLON, DARIEN, HERRERA, LOSSANTOS, ESTE, PMANORTE, METRO, SMGTO, VERAGUAS, KUNA_YALA, NGABE_BUGLE, P OESTE, R ARRAIJAN y R OESTE - se han mantenido los nombres originales sin acentos y otros caracteres - y se debe usar exactamente el mismo nombre, de lo contrario una hoja no sería procesado.
Note que la hoja País o Consolidado país no se procesa.
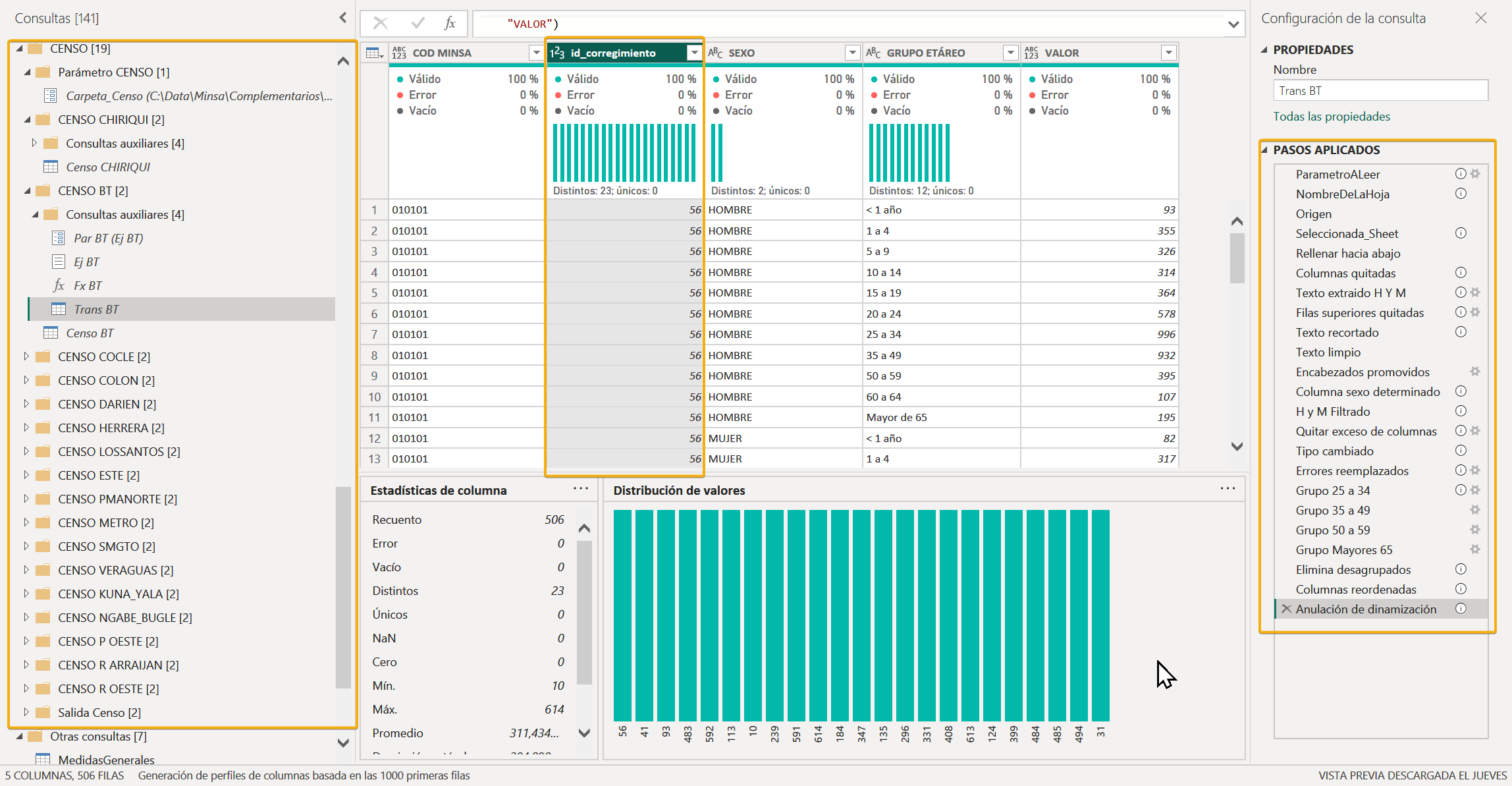
Las hojas de censo sufren unas modificaciones para convertirse de formato de hoja de Excel a un formato tabular, este proceso es aplicado a cada año y a cada hoja, el resultado es una consulta con datos que pueden ser usados por otros sistemas.
Consolidación del Censo
El proceso tiene en cuenta varios puntos clave en las hojas, por ejemplo en la columna de Sexo se analizan valores como Hombre, Mujer y Hombres y Mujeres, las filas que contienen el texto en plural son descartadas pues se consideran subtotales, así que cada fila con valor en singular (hombre, mujer) el sistema lo tiene en cuenta.
Adicionalmente de las hojas y el valor en singular, los nombres de las columnas de grupos etáreos del censo no deben ser cambiados pues se usan para categorizar y agrupar según la dimensión de grupo etáreo de SISVIG.
Finalmente, se debe insertar o mantener el código MINSA (útil para otras instituciones) y el id corregimiento (id de la tabla corregimientos de SISVIG).
El flujo de datos consolidará cada hoja de población y lo entregará como única tabla llamada CensoPanamá, con los campos antes mencionados.
En resumen: Insertar un nuevo año de datos para Censo se podría resumir en usar la plantilla proporcionada o tomar el archivo del año anterior y actualizar los datos de población - manteniendo la estructura y los códigos MINSA y id corregimiento, el sistema actualizará con datos del nuevo año - es importante mantener la estructura de nombres de archivo como “Población2024.xlsx, Población2025.xlsx” y así sucesivamente.
Si eventualmente se desea ajustar un valor de población de un año en un corregimiento en particular, es cuestión de ir al archivo del año, ubicar el corregimiento y realizar el ajuste - esto es viable desde Microsoft Excel en OneDrive con los permisos correspondientes.
El flujo de datos de censo
Un flujo de datos en Power BI es un conjunto de operaciones realizadas previamente y cuyo resultado se desea compartir con terceros (otras personas en la organización, otros sistemas de información o hasta otras entidades).
Esto permite que la extracción y transformación (compleja o no) que pueda tener una unidad de información pueda realizarse “tras bambalinas” y posteriormente ser compartida por el autor, en este caso el sistema de reportes de Power BI - cabe anotar que requiere uso de licencia PRO.
El flujo de datos de censo (y otros flujos) han sido publicados por el usuario Control (ver triada de gestión de información), así que un usuario de la organización (MINSA) podría acceder a estos, comúnmente desde Power BI al obtener datos - y con los permisos correspondientes - el sistema muestra algo similar a lo siguiente:
Una vez leídas las estructuras, tenemos lo siguiente:
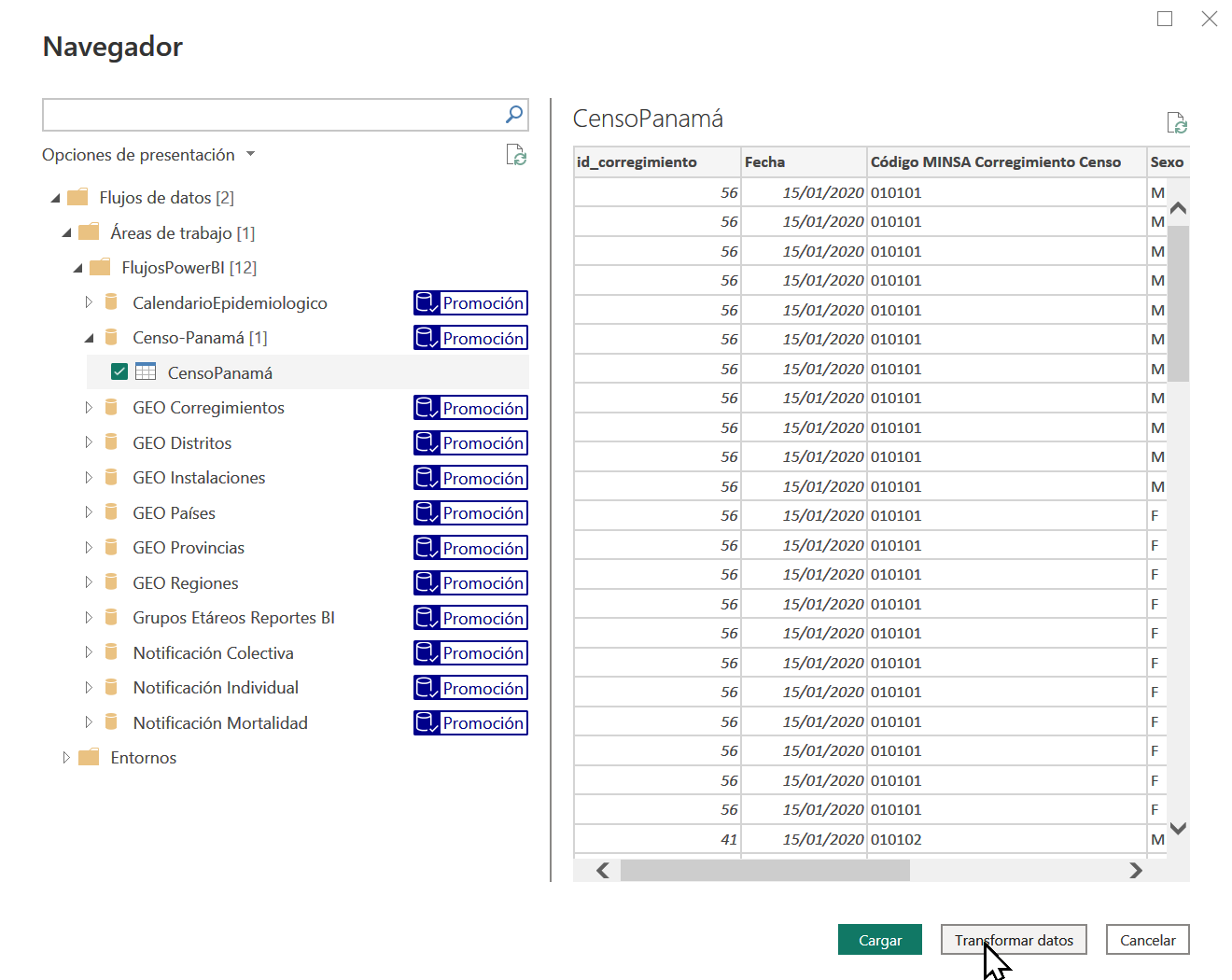
Actualmente se han compartido los flujos de datos de geografía, grupos etáreos, censo y datos de notificación individual, colectiva y mortalidad.
En esta pantalla podemos cargar los datos ya pre procesados o incluso realizar más transformaciones como por ejemplo filtrar años que no requerimos u otras tareas y ajustes.
Sugerencia: los flujos de datos permiten entregar una data de “interés público” ya transformada y pre procesada a usuarios que lo requieran, permiten también disminuir los requerimientos de procesos de un reporte, ya que el “esfuerzo” es realizado por los servicios de Microsoft, se sugiere usar esta estrategia para entregar información.
¿Editar el flujo de datos?
De entrada la respuesta rápida es: En la mayoría de los casos puede ser simple, pero el censo es posiblemente uno de los flujos de datos más complejos que se puedan crear, por ende evite la edición del mismo pues está compuesto de una buena cantidad de archivos, consultas y consolidaciones que pueden llegar a ser un reto para la mayoría de usuarios.
Cada hoja consolidada se lee en todos los archivos disponibles, crea una función y una consulta que consolida todos los años, posteriormente se unen todas las hojas, cada consulta puede tener una buena cantidad de pasos internos .
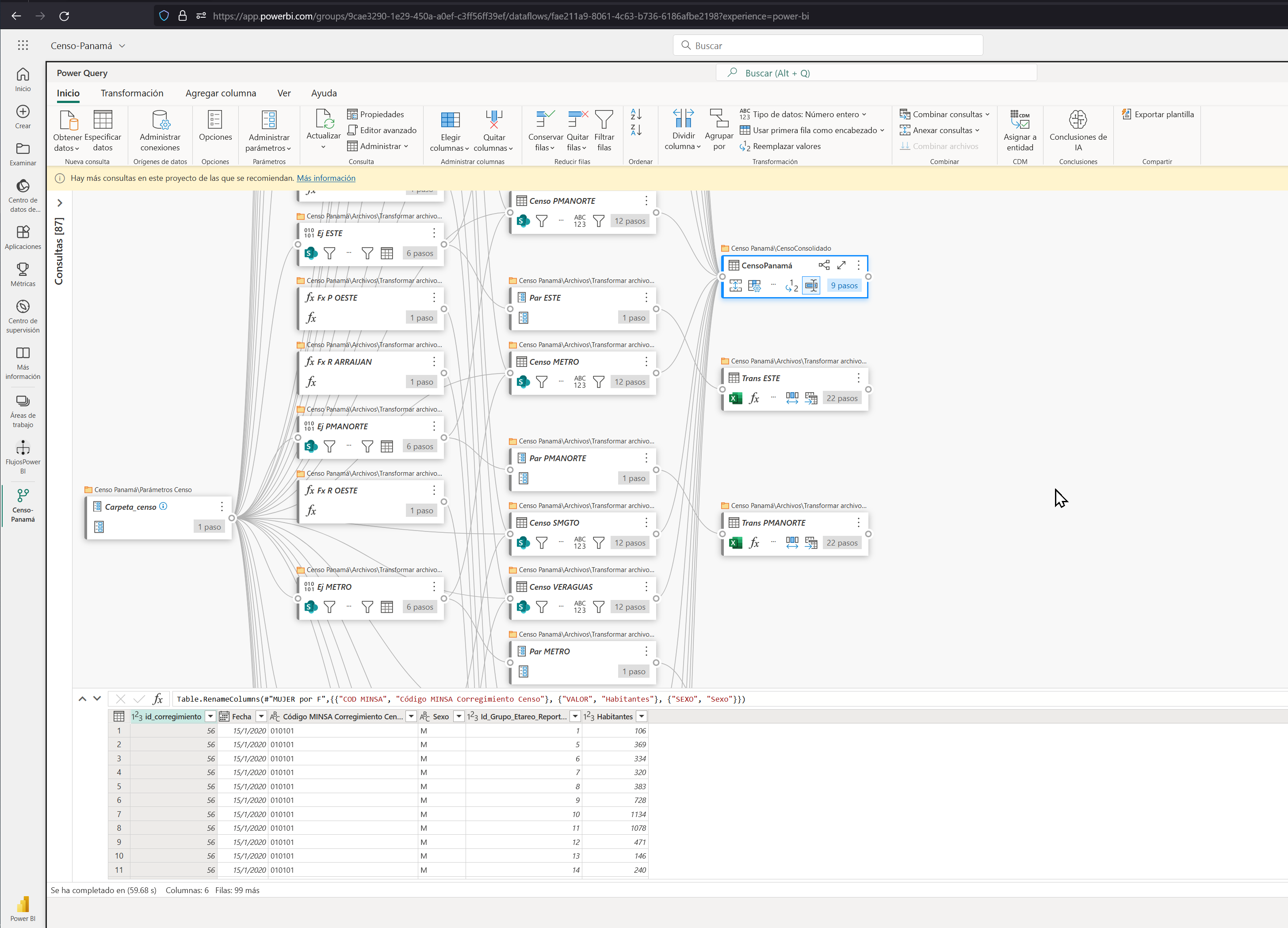
El sistema de Microsoft advierte que existen muchas consultas en el mismo script, es normal pero reitera la complejidad del script.
En resumen, acceda al script sólo si tiene buenos conocimientos de scripts para Power Query y comprende las consultas en el flujo de datos, recuerde que este sistema no permite realizar copias o duplicar un script que esté siendo usado en reportes, por lo cual es posible que un mal cambio lleve a un mal funcionamiento del sistema de reportes.